# 세미나 일정 : 2023 / 01 / 27
# 목적 : LPCV 대회 참가를 위한 study
틀린점이 있다면 댓글 남겨주시면 감사합니다 (❁´◡`❁)
IMFORMATION
본 논문은 IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 에 publish 된 논문이다. 논문의 저자는 메릴렌드 볼티모어 카운티 대학의 computer vision lab (BINA LAB) 에서 박사과정 진행중인 학생이며, 이전 연구에서 이와 유사한 연구를 진행 하였다. 이전 연구를 살펴본 결과 본 연구는 후속 연구라 생각된다.
TMI
본 논문을 study 한 이유는 올해 4학년에 진학하며 졸업프로젝트를 내가 속해있는 연구실의 교수님 과제를 진행하게 되었는데, 본 프로젝트는 LPCV 경진대회에 참가하는 것을 target 으로 하고 있어 자연재해 UAV dataset 을 이용한 segmentation model 에 대해 study 하기위함이다.
TTENTION BASED SEMANTIC SEGMENTATION ON UAV DATASET FOR NATURALDISASTER DAMAGE ASSESSMENT
Full paper : https://arxiv.org/abs/2105.14540
Attention Based Semantic Segmentation on UAV Dataset for Natural Disaster Damage Assessment
The detrimental impacts of climate change include stronger and more destructive hurricanes happening all over the world. Identifying different damaged structures of an area including buildings and roads are vital since it helps the rescue team to plan thei
arxiv.org
previous research
Comprehensive Semantic Segmentation on High Resolution UAV Imagery for Natural Disaster Damage Assessment
Full paper : https://ieeexplore.ieee.org/abstract/document/9377916
Comprehensive Semantic Segmentation on High Resolution UAV Imagery for Natural Disaster Damage Assessment
In this paper, we present a large-scale hurricane Michael dataset for visual perception in disaster scenarios, and analyze state-of-the-art deep neural network models for semantic segmentation. The dataset consists of around 2000 high-resolution aerial ima
ieeexplore.ieee.org
LPCV CHALLENGE
https://lpcv.ai/2023LPCVC/program
LPCV - Low Power Computer Vision
Disasters like floods and earthquakes threaten human safety, infrastructure, and natural systems. Every year, disasters kill an average of 60,000 people, affect 200 million and cause $150 billion (USD) billion in damage. A timely and accurate understanding
lpcv.ai
INTRODUCTION
먼저 본 논문의 저자는 자신의 연구 배경의 대해 설명한다.
Current
1. 첫번째로, Semantic Segmentation 은 cityscapes dataset 이나 PASCAL VOC dataset 에 대해서 꽤나 많은 연구와 방법들이 제안 되었지만, natural disaster dataset 에 대해선 dataset 자체가 제안되거나 이를 적용한 방법들이 적다는 점을 서술한다.
2. 두번째로, cityscapes dataset 이나 PASCAL VOC dataset 와 같은 Non-disaster dataset 은 Self-attention 기반의 model 들이 제안되어 오고 있지만 논문의 저자가 아는 한, disaster dataset 를 이용한 semantic segmentation 의 대한 self-attention 기반의 모델은 제안되지 않았다고 서술한다.


(논문을 한마디로 표현하자면) 따라서 본 논문의 저자는 Natural disaster dataset 을 적용한 self-attention 기반의 semantic segmentation model 을 제안한다.
Proposed
논문의 저자가 제안한 모델 이름은 ReDNet 이다.
ReDNet 은 ResNet 기반의 Dual attention 방법을 사용했으며, attention module 을 직접 설계하여 사용한다. 이는 PAM 으로 Position Attention Module 의 약자이다. 또한 dataset 으로 HRUD ( High Resolution UAV Dataset ) 을 사용한다. 본 dataset 은 위에서 언급했던 저자의 이전 연구와 관련된 dataset 이다.
HRUD 에 대해 간단히 짚고 넘어가자면,
위 previous research 에서 Full paper 를 확인 할 수 있으며, IEEE Big Data 2020 에 publish 된 연구이다. 저자는 자연재해 dataset 을 제안하며 최근 주요한 sementic segmentation model 들을 통해 dataset 을 평가하는 실험을 진행한다. 실험 결과는 아래와 같다.

HRUD dataset의 image는 3000x4000 해상도를 가지고 있으며, 9개의 calss label 을 가지고 있다. 예시 데이터는 아래와 같다.

저자는 UAV 데이터를 이용한 이미 제안된 방법들은 flood water, damaged road, building destruction 같은 것들을 다루었지만, 본 데이터 셋을 이용하며 폭넓게 segmentation 을 한다는 장점을 서술한다.
RELATED WORKS
위 이전 연구에서 평가한 3개의 모델을 RELATED WORKS 에서 다룬다. 이는 각각의 모델의 특징과 비교하기 위함이며, 이전 연구에서 사용한 평가와 저자가 구현한 모델의 대한 평가를 비교하기 위함으로 보여진다.
Enet ( ICLR 2017 )
Adam Paszke, Abhishek Chaurasia, Sangpil Kim, Eugenio Culurciello. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. ICLR 2017 conference submission 04 Nov 2016.
Enet 은 인코더 디코더 기반의 모델이라 할 수 있다. 이는 U-Net 과 비슷한 구조를 갖지만, shortcut 이 존재하지 않는 차이점이 보인다.


위와 같이 botleneck 을 사용하며 convolution 을 진행하고 encoder 에서 down-sampling을 decoder 에서 up-sampling 을 진행한다.
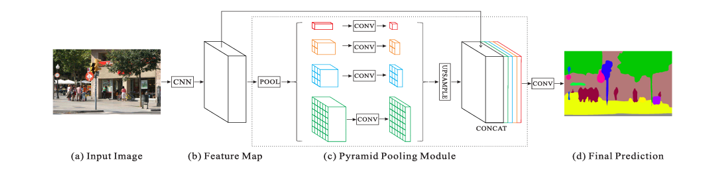
PSPNet ( CVPR 2017 )
Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia; Pyramid Scene Parsing NetworkProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2881-2890
PSPNet 의 특징은 인코더 디코더 기반이 아닌 Pyramid Pooling Module 을 사용한 점이다.
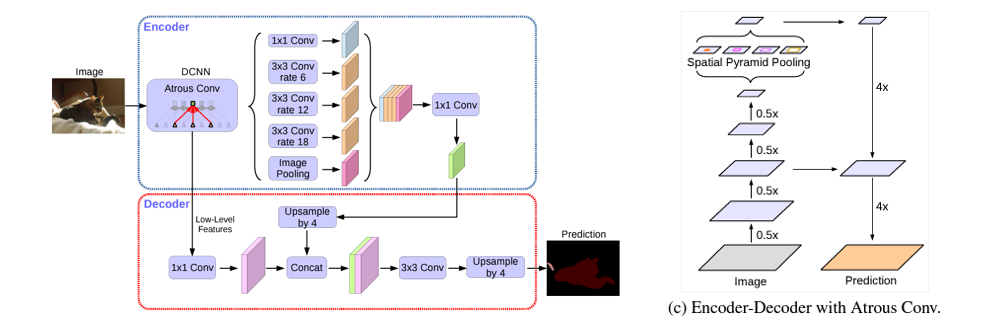
DeepLabv3+ ( ECCV 2018 )
Chen, LC., Zhu, Y., Papandreou, G., Schroff, F., Adam, H. (2018). Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11211. Springer, Cham. https://doi.org/10.1007/978-3-030-01234-2_49
DeepLabv3+ 는 sementic segmentation 분야에서 SOTA 성능을 달성한 모델이다. 본 논문을 자세히 읽어 보진 않았지만 검색을 통해 많은 review 와 정리를 찾아 볼 수 있듯이 뜨거운 issue 인 모델이라 생각한다.
본 모델의 주요 특징은 Atrous Conv 를 사용한다는점, Pyramid Pooling 을 사용한다는 점, Encoder-Decoder 형태를 가진다는 점이다.
METHOD

ReDNet은 위와 같은 아키텍처를 띄고 있는데, 이미지 input 에 대해서 resnet 을 통해 feature map / embeding Featrue 를
PAM (position Attention Module) 을 통해 Attention map 을 각각 만든 다음 Fusion 을 진행한다.
Dual Attention 을 사용한 이유를 보자면,
본 연구는 ResNet-101 을 backbone으로 사용하였는데, ResNet 은 각각의 stages 가 다른 특징을 갖고있다. lower stages는 spatial information 을 잘 encoding 하지만 receptive field 가 상대적으로 작기 때문에 semantic consistency는 나쁘다는 점을 갖고 있다. 반면에 Higher stages 는 semantic consistency는 좋은 경향을 보이지만, spatial information의 encoding은 나쁜것을 보인다. 따라서 Lower Stages (본 모델에서는 2 stages)의 output 과 higher stages(본 모델에서는 3 stages) output 을 각각 Position attention module의 input 으로 사용하여 두 stage 의 장점을 살리는 효과를 기대 하기 위해 Dual Attention 을 사용한다.

PAM 을 자세히 보자면 일반적인 vision-transformer의 self-attention 기법과 유사함을 보인다. B,C,D 는 Qurry, Key, Value 로 표현 할 수 있다고 생각한다.
먼저 input 으로 들어온 A feature 를 Convolution Op를 통해 각각 B, C, D 의 feature map 을 만들고 그림과 같이 연산을 진행한다. 여기서 Reshape 를 하는 이유는 최대한 input A 의 크기를 맞춰주기 위함이다.
모든 연산을 진행하면 output 으로 input A 와 같은 shape 을 갖는 attention map 을 출력한다.
EXPERIMENTS


실험 결과를 보자면 본 논문에서 제안한 ReDNet은 비교한 다른 Model 보다 뛰어난 성능을 보이는 것을 확인 할 수 있다.
CONCLUSION
정리를 해보자면 논문의 저자는 High resolution UAV dataset 을 적용한 self-attention 기반의 semantic segmentation model 을 구현 하였으며, 평균 IoU 가 88% 정도 달성 한 것으로 나타난다.




댓글