# 세미나를 위한 논문 summary
# 2022 MobiSys에서 발표된 논문
# 오역이 있을 수 있습니다.
# 2022 08 30 seminar
# ACM reference Format : JongseokPark,KyungminBin,andKyunghanLee.2022.mGEMM:LowlatencyConvolutionwithMinimalMemoryOverheadOptimizedforMobile Devices.InThe20thAnnualInternationalConferenceonMobileSystems, ApplicationsandServices(MobiSys’22),June25–July1,2022,Portland,
https://dl.acm.org/doi/10.1145/3498361.3538940
mGEMM | Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services
ABSTRACT The convolution layer is the key building block in many neural network designs. Most high-performance implementations of the convolution operation rely on GEMM (General Matrix Multiplication) to achieve high computational throughput with a large w
dl.acm.org
https://strangecat.tistory.com/71 ( 1 )
https://strangecat.tistory.com/74 ( 2 )
https://strangecat.tistory.com/75 ( 3 )
https://strangecat.tistory.com/82 ( 4 )
##
##
5 EXPERIMENTAL EVALUATION
5.1 Experimental Setup
알고리즘에 대한 철저하고 포괄적인 평가를 수행하기 위해, 우리는 세 가지 다른 측면에 초점을 맞춰 실험을 설계한다.
Test Devices :
모바일 장치의 범위는 매우 다양하며, 각각은 다양한 측면에서 다양하다. 테스트 장치는 저렴한 단일 보드 컴퓨터부터 플래그십 스마트폰에 이르기까지 다양한 모바일 장치에 적용되도록 선택되었다. 기존 장치가 알고리즘을 사용하여 얻을 수 있는 진정한 이점을 결과를 확실히 보여주기 위해 재고 설정에서 기성 장치를 사용한다.
Software : ARM에는 다양한 컨볼루션 솔루션이 있다. 우리는 비교를 위한 테스트에 널리 사용되는 솔루션과 경쟁력 있는 솔루션을 모두 포함한다. 시간, 메모리 및 에너지의 결과는 우리 솔루션의 우수성을 보여줄 뿐만 아니라 모바일 컴퓨팅의 다차원 측면에 대해 추측하기 위해 제공된다.
Benchmarks : 우리는 VGG-16[40], ResNet-50[17] 및 MobileNet V2[39]의 세 가지 다른 CNN의 컨볼루션 레이어를 테스트한다. 우리는 또한 객체 감지 네트워크인 YoloV3-Tiny[38]를 사용하여 종단 간 애플리케이션 작업에 대한 결과를 포함한다. 우리가 선택하는 각 CNN은 고전적이고 현대적이며 모바일 중심의 CNN 설계를 나타낸다. 많은 네트워크가 모바일에 특별히 중점을 두지 않고 설계되고 여전히 모바일에 배치되기 때문에 우리는 일반성을 위해 모바일 중심 CNN에 대한 테스트를 제한하지 않는다.
5.1.1 Test Devices. 우리는 각각 저비용, 중간 계층 및 고급 플랫폼을 나타내는 서로 다른 수준의 하드웨어 성능을 가진 세 개의 ARM 기반 플랫폼에서 실험을 실행한다. 각 장치의 사양은 표 2에 나와 있다.

5.1.2 Software. 우리는 기본 im2col + GEMM, 두 개의 고성능 DNN 라이브러리, [52]를 기반으로 C++로 직접 작성하는 direct 컨볼루션 방법을 포함하여 다양한 기존 GEMM 기반 컨볼루션과 비교하여 알고리즘을 테스트한다.
im2col + OpenBLAS: Caffe[23]의 원본 im2col 코드를 기반으로 C++에서 im2col 루틴을 구현합니다. OpenMP[7]를 사용하여 im2col에 멀티 스레딩을 적용하고 결과를 OpenBLAS[50] 라이브러리에서 제공하는 고성능 GEMM 루틴으로 파이프했다. OpenBLAS를 im2col 루틴과 결합하는 이러한 접근 방식은 최근 많은 연구에서 참조 솔루션으로 사용된다[1, 20, 52, 54]. GEMM 기반 컨볼루션의 낮은 노력과 우수한 성능 구현을 제공한다.
ARMNN: ARMNN[3]은 더 높은 수준의 NN 프레임워크에 다양한 신경망 루틴을 제공하도록 설계된 ARM의 자체 고성능 DNN 라이브러리이다. ARMNN의 백엔드로, 우리는 ARM의 컴퓨팅 라이브러리[4]를 사용했다. 컴퓨팅 라이브러리는 ARM CPU 및 GPU 설계에 최적화된 고성능 컴퓨팅 커널의 모음이다.
XNNPACK: 우리가 사용하는 또 다른 고성능 신경망 라이브러리는 Google의 XNNPACK[12]이다. XNNPACK은 TensorFlow Lite, Ruy의 기본 백엔드에 비해 훨씬 빠른 성능을 제공하며 마이크로아키텍처 수준에 최적화된 손으로 코딩된 커널을 사용한다[10]. TensorFlow Lite와 Ruy가 더 인기가 있지만 더 경쟁력 있는 비교를 위해 XNNPACK을 선택한다.
우리의 비교 대상에는 모두 광범위한 하드웨어, 알고리즘 및 형식에 대해 고도로 최적화된 다양한 계산 커널이 포함된다. 비교에 대한 공평한 근거를 제공하기 위해 CPU, GEMM 기반 솔루션 및 단정밀도 부동 소수점을 대상으로 하는 커널만 사용하도록 이러한 라이브러리를 컴파일한다. 가지치기 또는 양자화와 같이 테스트의 정확도를 변경하는 최적화 기술은 해제되지만 하드웨어 가속(예: NEON SIMD 가속, 다중 스레딩) 또는 GEMM 최적화( 예를 들어 타일링, 배열 패킹)은 그대로 유지된다.
모든 테스트는 일반적인 모바일 시나리오를 나타내기 위해 사용 가능한 모든 코어를 활용하면서 하나의 배치 크기로 실행된다. im2col + OpenBLAS, XNNPACK 및 ARMNN 테스트에 NHWC의 메모리 레이아웃을 사용하여 최상의 성능을 달성했다.
섹션 3에서 언급했듯이 모든 계산 방법은 수학적으로 동일하므로 부동 소수점 표현과의 사소한 차이점을 제외하고 결과는 변경되지 않은 상태로 유지되어야 한다. 모든 테스트 사례에서 결과와 네트워크의 정확도가 모든 계산 방법에 대해 동일하게 유지됨을 확인한다.
5.2 Performance Evaluation


5.2.1 Classical Convolutions. 그림 6은 VGG-16[40] 및 ResNet-50[17]의 traditional non-pointwise 컨볼루션 레이어에서 기존 GEMM 기반 솔루션과 비교하여 mGEMM 컨볼루션 커널의 latency 를 보여준다. 우리의 방법은 모든 테스트 장치에서 거의 모든 계층에서 기존 솔루션을 능가한다. 우리는 XNNPACK과 비교하여 1.66 ×, ARMNN과 비교하여 1.47 ×, im2col + OpneBLAS와 비교하여 2.81 ×의 평균 속도 향상을 달성한다. 기존 솔루션의 성능은 네트워크, 계층 및 장치에 따라 크게 달라지는 경향이 있어 확실한 승자가 없다. mGEMM만이 전반적으로 안정적인 성능을 보여 다른 제품보다 성능이 우수하다.
그림 6(a)의 L1과 같이 mGEMM이 더 느린 성능을 보인 경우가 있는데, 이 경우 mGEMM은 여전히 가장 빠른 것의 10% 내에서 경쟁력을 유지한다. 우리는 입력 텐서의 크기와 계산 수가 너무 작아서 이러한 계층에서 우리 솔루션의 이점이 크지 않다고 생각한다. 이와 같이, 이러한 계층과의 지연 시간 차이는 우리가 다른 계층에서 가지고 있는 큰 속도 향상과 비교할 때 본질적으로 중요하지 않다.
5.2.2 Depthwise and Pointwise Convolutions. 그림 7은 MobileNet V2(1.4x)의 포인트별 및 깊이별 레이어에서 기존 GEMM 기반 솔루션과 비교하여 mGEMM 컨볼루션 커널의 레이턴시를 보여준다. im2col + GEMM[5] 및 direct 컨볼루션 방법[52]은 깊이별 컨볼루션 계산을 위한 접근 방식을 지정하지 않기 때문에 깊이별 컨볼루션 테스트에 포함시키지 않았다.
( MobileNet V2 with 224×224 input size )
깊이별 레이어에서, 우리의 방법은 지배적인 성능을 보여주었다. 우리의 커널은 일부 계층에서 최대 16배 속도 향상을 달성하며, 모든 장치의 모든 계층에서 XNNPACK에 대해 최소 1.41배, ARMNN에 대해 1.76배 속도 향상을 유지한다. 섹션 3에서 언급했듯이 포인트별 컨볼루션에서 mGEMM 커널과 기존 GEMM 커널의 차이는 미미하다. 그럼에도 불구하고, mGEMM은 이러한 계층의 기존 솔루션보다 더 빠르거나 적어도 경쟁력이 있다.
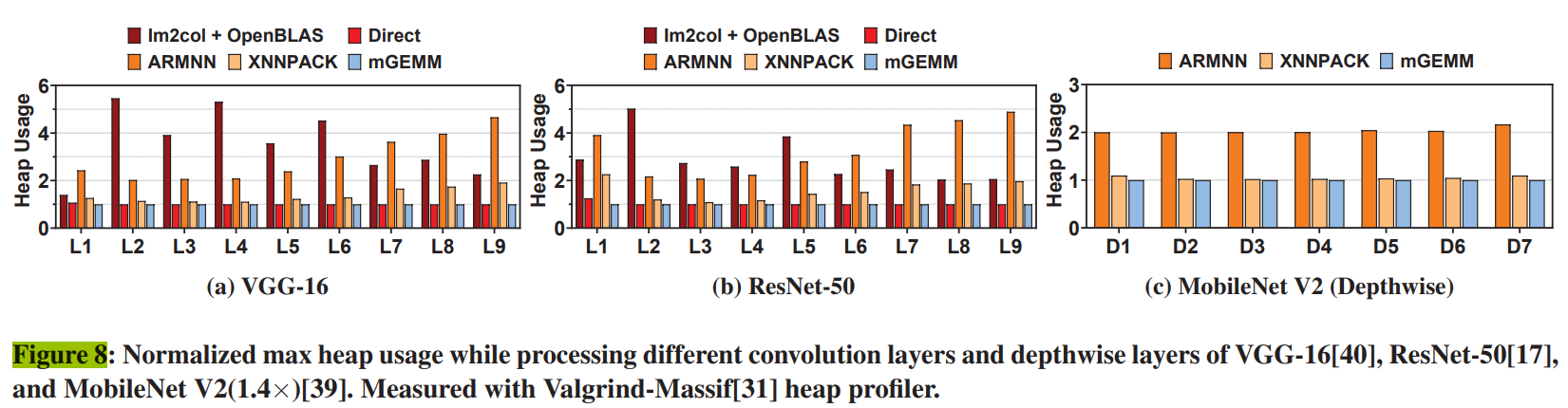
5.2.3 Memory Usage per Layer. 그림 8은 VGG-16[40], ResNet-50[17]의 non pointwise 레이어와 MobileNet V2(1.4×)[39]의 depthwise 레이어의 정규화된 최대 힙 메모리 사용량을 보여준다. Valgrind-Massif[31]는 테스트 프로그램의 힙 할당을 기록하여 작동하므로 출력은 장치 독립적이다. 각 솔루션의 최대 힙 사용량을 각 계층의 입력, 출력 및 필터 텐서를 저장하는 데 필요한 이론적 최소 메모리 공간으로 정규화했다. 추가 메모리 공간 없이 직접 계산할 수 있는 pointwise 레이어는 포함하지 않았다. 우리의 mGEMM 커널과 direct 컨볼루션 방법[52]은 메모리 오버헤드가 없는 솔루션이므로 추가 메모리 공간이 필요하지 않다. 반면 im2col + OpenBLAS와 ARMNN은 최소 메모리 풋프린트에 1.4배에서 5.5배, 더 최적화된 XNNPACK은 1.1배에서 2배이다.
5.2.4 End to End Application Latency. 객체 감지와 같은 실제 애플리케이션에서 컨볼루션 알고리즘의 이점을 측정하기 위해 객체 감지 네트워크를 종단 간 실행하면서 여러 컨볼루션 솔루션의 지연 시간, 메모리 사용량 및 에너지 소비를 비교한다. 다크넷[37] 신경망 프레임워크에서 인기 있는 YoloV3-Tiny[38]를 물체 감지 네트워크로 사용했다. 우리는 네트워크의 컨볼루션 작업이 우리가 선택한 라이브러리에 연결될 수 있도록 다크넷 프레임워크를 수정한다. 모든 비컨볼루션 작업은 다크넷 프레임워크를 사용하여 처리되며, 이는 성능 차이를 컨볼루션 레이어의 성능으로만 제한하기 위함이다. 우리는 Monsoon 전력 모니터[30]를 사용하여 네트워크를 실행하는 동안 장치의 에너지 소비량을 측정했다.
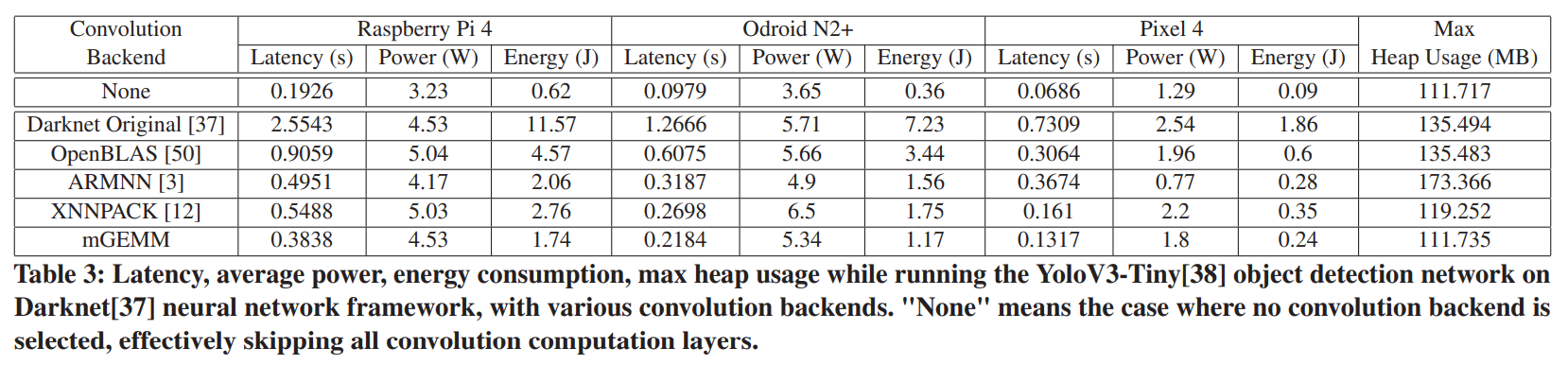
표 3은 테스트 장치에서 실행되는 5가지 다른 컨볼루션 백엔드의 YoloV3-Tiny 객체 감지 성능을 보여준다. mGEMM은 각 장치의 두 번째로 빠른 솔루션과 비교하여 대기 시간에서 22%에서 29%의 속도 향상을 달성하며, 이는 또한 유사한 비율로 에너지 소비를 줄이는 동시에 모든 컨볼루션 레이어를 건너뛰어 측정한 이론적 최소값보다 0.018MB만 더 많이 사용한다.
흥미롭게도 mGEMM은 거의 모든 parameter 에서 다른 방법보다 성능이 뛰어나지만 전력 사용량에서는 일관되게 ARMNN보다 성능이 뛰어납니다. 그러나 계산 지연 시간이 길기 때문에 ARMNN의 에너지 사용량이 mGEMM보다 지속적으로 더 높다는 것은 평균 전력의 차이가 mGEMM이 ARMNN보다 전력 효율성이 낮기 때문이 아니라 mGEMM은 대기 시간을 줄여 장치 활용도를 높이는 것을 목표로하기 때문에 나타낸다. mGEMM은 더 나은 평균 전력(즉, 열 특성)을 위해 계산 밀도를 낮추는 것을 선택할 수 있지만, 우리의 초점은 모바일을 위한 single-shot, 낮은 지연 시간 컨볼루션에 있기 때문에, 우리는 가장 낮은 지연 시간, 메모리 및 에너지에 최적화한다.
6 DISCUSSION
Hardware acceleration: 많은 모바일 플랫폼에는 GPU나 NPU와 같이 CPU보다 계산 처리량이 높은 하드웨어가 포함되어 있다. mGEMM은 GEMM에 비해 알고리즘적으로 개선된 것이기 때문에, mGEMM은 또한 그러한 가속기의 높은 성능으로부터 이익을 얻을 수 있다. 그러나, 더 고려해야 할 몇 가지 문제가 있다. 이러한 프로세서는 종종 초기화 및 데이터 이동에 대한 오버헤드를 요구하므로, 계산의 전체 지연 시간은 CPU의 지연 시간보다 클 수 있습니다. 더욱이, 이러한 프로세서의 높은 처리량을 활용하기 위해서는 하드웨어를 포화시키고 오버헤드를 상각하는 데 큰 배치 크기가 필요하며, 모바일 상황에서는 이러한 배치 크기를 사용할 수 없는 경우가 많다.
이론적으로, mGEMM은 traditional GEMM 기반 알고리즘보다 가속기에서, 특히 모바일에서 더 효율적으로 수행될 가능성이 있다. 모바일 SoC의 하드웨어는 종종 동일한 메모리 버스를 공유하기 때문에, 가속기에 사용할 수 있는 메모리 대역폭은 더 높은 계산 처리량에도 불구하고 CPU의 그것과 비슷할 것이다. 즉, 높은 계산 처리량을 적절히 활용하려면 로드된 데이터를 더 많이 재사용해야 한다. 따라서 mGEMM에서 메모리 오버헤드를 제거하고 더 높은 산술 강도를 사용하면 GEMM 기반 알고리즘에 비해 모바일 가속기의 성능이 향상될 것으로 믿는다.
JIT Compilation & Auto-Tuning: GEMM 커널은 종종 M, N 차원 blocking prameters 의해서만 정의되지만, 우리의 커널은 c(o)와 w(o) 외에도 stride, dilation, padding과 같은 추가 변수에 의존한다. 이는 GEMM에 비해 제공해야 하는 내부 커널의 수를 증가시킨다. JIT(Just-In-Time) 컴파일 및 자동 성능 튜닝 또는 필요한 커널의 자동 조정을 솔루션으로 사용할 것을 제안한다. JIT 컴파일과 자동 조정은 종종 GEMM 솔루션에서 결합되어 주어진 장치에 최적화된 커널을 동적으로 생성한다. 주어진 모델에 필요한 커널은 항상 미리 결정되기 때문에 고성능 커널은 배포 전에 쉽게 JIT 컴파일될 수 있으며, 그 비용은 여러 추론에 걸쳐 상각된다.
Quatizations: 계산 복잡성을 줄이고 처리량을 늘리기 위해 정밀도 형식을 낮추기 위한 양자화는 모바일에서 일반적이다. 양자화를 통해 한 번에 더 많은 수의 작은 데이터에 대해 작동함으로써 총 계산 및 메모리 액세스 작업의 거의 비례적으로 감소할 수 있다.이 변경은 더 큰 레지스터를 가지므로 섹션 4에서 더 큰 blocking parameters 를 갖는 것으로 이해할 수 있다. 이는 GEMM보다 mGEMM에 더 많은 이점이 있다. MAC당 메모리 연산을 계산할 때blocking parameters 가 선형적으로 사용되는 GEMM과 달리, mGEMM은 계산을 위해 parameters 를 곱한다. 따라서 blocking 크기가 클수록 mGEMM의 MAC당 메모리 동작이 더 크게 감소한다.
Large-scale impact of mGEMM: mGEMM은 YoloV3-소형 물체 감지 작업에서 대기 시간, 메모리 및 에너지를 눈에 띄게 개선할 수 있었지만, 대규모 시스템에서 이러한 개선의 영향과 그 영향이 모바일 하드웨어의 발전과 여전히 관련이 있는지 여부는 추가 검증이 필요하다. nn-Meter와 같은 연구는 우리에게 이러한 질문에 대한 힌트를 제공한다. nn-Meter의 데이터는 모바일 CPU와 GPU 모델 대기 시간의 많은 부분(80% 이상)이 광범위한 네트워크에서 컨볼루션 레이어(심도별 컨볼루션 포함)로 구성되어 있음을 보여준다. 이와 같이 mGEMM이 가져오는 컨볼루션 레이어의 개선은 대규모 모델을 기반으로 한 보다 정교한 서비스에 혜택을 줄 가능성이 높다. 또한 모바일에서 CNN 기반 솔루션의 사용과 복잡성은 모바일 하드웨어의 발전에 따라 확장될 것이기 때문에, mGEMM이 제공하는 컨볼루션 작업의 알고리즘적 개선은 하드웨어 개선에도 불구하고 이러한 CNN 기반 서비스에 지속적으로 도움이 될 것이다.
7 RELATED WORKS
우리의 작업은 주로 컨볼루션에 대한 계산 알고리즘을 최적화하는 데 중점을 두었다. 모바일 하드웨어에 특화된 네트워크 구조 또는 최적화도 모바일용 신경망을 가속화하기 위한 유효한 접근법이다. 우리는 다양한 측면에 초점을 맞춘 알고리즘 최적화뿐만 아니라 이러한 주제를 다루는 관련 작업을 간략하게 소개한다.
Network structures: MobileNet V1[19]은 깊이별로 분리 가능한 컨볼루션(convolution)을 사용하여 총 계산 수와 네트워크 크기를 크게 줄인다. MobileNet V2[39]는 반전 병목 레이어를 사용하여 깊이별 컨볼루션을 사용하기 전에 채널 수를 확장하는데, 이는 더 적은 계산 수와 네트워크 크기로 더 나은 정확도를 제공한다. Inverted Bottleneck layer 는 MnasNet[43] 및 EfficientNet[44]과 같은 많은 현대 효율적인 CNN 설계의 주요 구성 요소가 되었다.
Mobile hardware optimizations: Wang at al. big, LITTLE 이기종 클러스터 구성으로 인한 ARM CPU의 처리량 손실을 해결한다. 그들은 클러스터 간의 통신을 최소화하기 위해 여러 클러스터에 걸쳐 컨볼루션 레이어를 분할하는 파이프라인 구조를 구현합니다. Zhang et al. ARM Cortex-A CPU에 초점을 맞춘 pointwise(GEMM) 및 depthwise convolution을 최적화한다. ARM 아키텍처 전용 최적화를 통해 OpenBLAS 및 Ruy에 연결된 TFLite에 비해 더 높은 성능을 달성한다. Mogers et al. 타겟 GPU 아키텍처에 최적화된 직접 컨볼루션 코드를 생성할 수 있는 모바일 GPU용 데이터 병렬 중간 언어 및 컴파일러를 제공한다.
Algorithmic optimizations: Gural 등은 컨볼루션 알고리즘의 메모리 사용에 대해 극단적인 최적화를 수행하고 2KB의 메모리만으로 MNIST-10 분류 작업을 성공시킨다. 인상적이긴 하지만, 이 기술은 메모리 감소를 위해 계산 시간을 많이 희생한다. 단일 레이어에 초점을 맞춘 대부분의 작업과 달리 신경망의 그래프 기반 표현을 구성하고 최적화하여 레이어 간 최적화에 초점을 맞춘 [26, 36]과 같은 작업도 존재하며, 이는 우리의 작업에 직교 장점을 추가할 수 있다.
8 CONCLUSION
제한된 메모리 기능과 모바일 CNN 추론의 low-latency repuirement 는 현재 GEMM 기반 컨볼루션 솔루션을 모바일용으로 는 덜 최적화한다. 메모리 오버헤드와 GEMM의 낮은 데이터 재사용률은 현재 솔루션이 모바일에서 직면한 두 가지 주요 문제이다. 우리는 컨볼루션을 GEMM에 매핑하는 과정을 분석하고 이러한 문제의 근본 원인을 확인했다. 이 분석을 기반으로, 우리는 앞서 언급한 문제를 제거하여 컨볼루션 연산을 보다 효율적으로 계산할 수 있는 계산 알고리즘인 mGEMM을 만든다. mGEMM의 구현은 다양한 테스트 플랫폼과 네트워크에서 대기 시간과 메모리 모두에서 기존 고성능 신경망 라이브러리를 능가하는 것으로 나타났다.




댓글