>> 본 과제는 학부연구생을 진행하며 수행한 내용을 복습 및 기록 하기 위해 작성 하였습니다.
GEMM >
>> 본 포스팅은 이전 포스팅에서 이어지는 내용입니다.
>> https://strangecat.tistory.com/53?category=998875
im2col_convolution lowering : C로 구현해보자!
>> 본 과제는 학부연구생을 진행하며 수행한 내용을 복습 및 기록 하기 위해 작성 하였습니다. Im2col > https://arxiv.org/abs/1410.0759 - cuDNN: Efficient Primitives for Deep Learning 본 논문은 nvidia..
strangecat.tistory.com
이전 포스팅에서 conv 대신 matmul을 진행하면 연산시간이 떨어진것을 확인할 수 있다고 작성하였다. 그렇다면 왜 그렇게 빨라지는지 확인해 보자.

위 그림인 Convolution Pseudocode 를 보면 1개의 이미지를 conv 할때 6중 포문을 돈다는 것을 알 수 있다.

위 그림인 Matmul Pseudocode 를 보면 3중 포문을 돈다는 것을 확인 할 수 있다.
이를 비교해 보았을때 아주 단순하게 생각해도 O(n^3) vs O(n^6) 으로 matmul 이 휠씬 빠르다는 것을 알 수 있다. 이와 같이 loop 의 수가 차이가 나는 이유에는 결국 im2col 에 해당한다. 이미지를 2-matrix 으로 변환 해 주었기 때문에 단순히 prameter 를 접근하는데 필요한 loop 가 conv 보다 많이 필요하지 않는다.
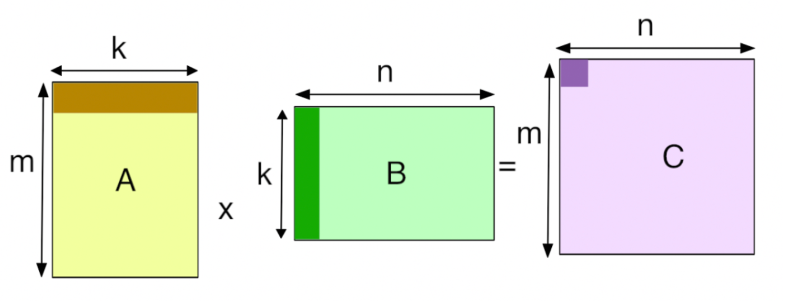
그림을 통해 설명 하자면, 그저 m, n, k 의 값을 고려 하여 loop 를 통해 각각의 prameter를 접근하여 연산 하면 된다.
하지만 conv 의 경우 image 가 3-tensor 이고 kernel 역시 3d 이면서 output_channel 을 가지고 있기 때문에 prameter 접근을 위해선 image 의 height, width, image_input_chenel, kernel 의 height, width, kernel_channel, kernel_number 로 굉장히 많은 경우를 따져야 한다.
하지만 장점이 있으면 단점도 있는법. GEMM 을 사용하는 경우 많은 meomory 가 필요하다는 점이 존재한다. im2col 을 수행하면 input_image 를 matrix 로 변환하면서 총 parameter 가 변한다.
우선 im2col 을 하기전에 크기에 맞는 새로운 memory를 할당 받아야 하며, 받은 메모리에 matrix 변환 된 image를 새로 할당 해주어야 한다.
그럼 어느정도의 메모리가 필요한가?

원래 input image 의 memory alloc 을 height * width * channel 만큼 해주었다면, im2col 과정을 거친 matrix 는 height * width * channel * kernel * kernel 만큼의 memory 가 필요하다.
하지만 현대에 들어오고선 가정집 컴퓨터에서 딥러닝 학습을 하는것이 아닌 이상 연구실이나 기업에서 사용할때 크게 문제되는건 아니라고 한다. 또한 memory overhead 가 크지만 이런것을 감안할 만큼 GEMM 은 효과적인 성능을 나타 낸다고 한다.
그럼 코드를 살펴 보자.
GEMM code >>
/*
int M : h * w
int N : oc
int K : c * k * k
float* A : im2col image
float* B : kernel
float* C : output
*/
void gemm(int transA, int transB,
int M, int N, int K,
float ALPHA,
float* A, int lda,
float* B, int ldb,
float BETA,
float* C, int ldc){
float sum = 0;
int hw, oc, ckk;
for(int hw= 0 ; hw < M ; hw++){
for(int oc= 0 ; oc < N ; oc++){
sum = 0;
for(int ckk = 0; ckk <K; ckk++){
sum += A[ckk + hw * K] * B[ckk + oc * K];
}
C[hw + oc * M] = ALPHA * sum;
}
}
}
코드를 보았을때 Matmul Pseudocode 와 크게 다른 점이 없다.
source code >>
https://github.com/sangho0804/darknet-based-CNN/blob/master/GEMM/GEMM.c
GitHub - sangho0804/darknet-based-CNN: for deep Learning CNN study
for deep Learning CNN study. Contribute to sangho0804/darknet-based-CNN development by creating an account on GitHub.
github.com
reference >>
https://shivathudi.github.io/jekyll/update/2017/06/15/matr-mult.html
Matrix multiplication using the Divide and Conquer paradigm
In this post I will explore how the divide and conquer algorithm approach is applied to matrix multiplication. I will start with a brief introduction about how matrix multiplication is generally observed and implemented, apply different algorithms (such as
shivathudi.github.io
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/328651622
'학부생의학부연구생 > _deep_learning' 카테고리의 다른 글
| im2col_convolution lowering : C로 구현해보자! (0) | 2022.06.22 |
|---|---|
| Convolutional layer : C로 구현 해보자! (2) (0) | 2022.03.30 |
| Convolutional layer : C로 구현 해보자! (1) (4) | 2022.03.17 |
| CNN이 뭐야? (0) | 2022.02.03 |
| 딥러닝이 뭐야? (0) | 2022.01.20 |



댓글